这些天的“上下文工程”有多受欢迎?菲尔·施密特(Phil Schmidt)
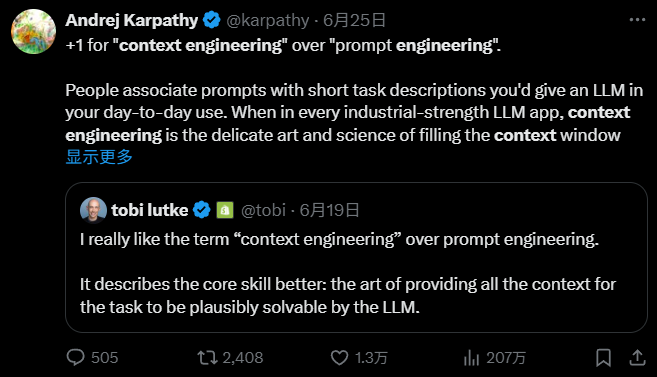 这些天的“上下文工程”有多受欢迎? Andrej Karpathy称其为“菲尔·施密德(Phil Schmid)上下文工程”发表的文章,进入了Hacker News的顶部和Zhihu Hot的搜索列表。我之前介绍了上下文的基本工程概念,但是今天我将解释实践练习。为何专注于“上下文工程”很容易化身份LLM:训练他们作为可以“思考”,“理解”,“混淆”和“混淆”的超级助手。从工程的角度来看,这是一个根本错误。 LLM是一个没有信念或意图的智能文本生成器。更精确的视觉是:LLM是一个常见且不确定的功能。这就是此函数的工作方式:给出文本(上下文)并生成新的文本(输出)。常规:这意味着您可以处理多个任务(翻译,代码编写等),而无需单独编程每个任务。我不确定:这意味着相同的入口和您每次都可以稍作不同。 Th是一个特征,而不是问题。没有状态:这意味着没有记忆。每次您输入“记住”对话时,都必须提供所有相关的背景信息。这种观点很重要,因为它定义了工作方法。您不能更改模型本身,但是您可以完全控制入口。所有优化的关键是如何构建最有效的输入文本(即上下文)。指导模型生成预期的出口。 “ Speedword Project”曾经很受欢迎,但强调要找到完美的魔法咒语。这种方法在实际应用中不可靠。这是因为模型更新可以使“咒语”失败,而真实的输入比单个语句中的说明要复杂得多,比单个语句中的说明更为复杂。更精确,更精确的系统概念是“上下文工程之间的差异”。背诵咒语。上下文工程:A是为了构建自动化系统,例如信息管道的设计。该系统负责在完整上下文中包装,然后在模型中对数据库,文档等上的信息自动跟踪和合并信息。正如Andrej Karpathy所说,LLM是一种新型的操作系统。我们的任务不是给出零碎的命令,而是容纳执行它们所需的所有数据和环境。简而言之,“上下文工程”是关于创建“超级入口”工具箱。我们听到的各种时尚技术(耳朵,代理等)只是此工具箱中的工具。只有一个目标。它是以最合适的格式和最合适的时刻以最有效的信息来馈送最有效的信息。以下是工具箱的一些中心元素:指令:问题命令是最基本的。这意味着直接告诉模型该怎么做。例如,订购“玩专家”或显示一些示例nd让他们相应地学习。知识:您必须记住要指出“内存”在模型本身中没有内存。聊天机器人在他身上,一起发送聊天记录。如果记录太长,请创建“摘要”或仅保留最后的对话。工具:改进的生成搜索(RAG):为“开放书考试”提供参考书。为了防止毫无意义的含义模型(骆驼),首先找到其知识库的相关信息(例如公司文档),然后将“参考”和问题传递给模型,以便您可以客观地回答。特工:请单独“验证”。这是一个高级formhas的演出。我们不再预先准备所有信息,而是一个智能的“机构”确定您需要哪些信息,然后使用工具(例如搜索互联网或搜索数据库)查找答案并总结它们以最终解决问题。简而言之,所有这些技术,无论是简单的还是复杂的,都可以回答此任务n。 “如何为LE创建最完美的条目?”上下文工程的实用方法使用了执行科学实验而不是艺术创作的LLM。您不能相信猜测。您必须批准测试并进行验证。工程师的主要功能不是编写引人注目的建议,而是知道如何通过系统不断改进系统。首先,清楚地考虑LLM输出(内容,格式等)的终点。最终组装),开始建筑物。它完成了“精细的组装测试”。VEA当前常规的上下文工程的最新博客和视频详细介绍了四种中心方法,并显示了Langgraph和Langchain生态系统的Langgraph和Langsmith如何帮助开发人员有效地实施上下文工程。博客地址:共同代理的NTEXT工程视频地址:代理上下文工程(Langchain)
这些天的“上下文工程”有多受欢迎? Andrej Karpathy称其为“菲尔·施密德(Phil Schmid)上下文工程”发表的文章,进入了Hacker News的顶部和Zhihu Hot的搜索列表。我之前介绍了上下文的基本工程概念,但是今天我将解释实践练习。为何专注于“上下文工程”很容易化身份LLM:训练他们作为可以“思考”,“理解”,“混淆”和“混淆”的超级助手。从工程的角度来看,这是一个根本错误。 LLM是一个没有信念或意图的智能文本生成器。更精确的视觉是:LLM是一个常见且不确定的功能。这就是此函数的工作方式:给出文本(上下文)并生成新的文本(输出)。常规:这意味着您可以处理多个任务(翻译,代码编写等),而无需单独编程每个任务。我不确定:这意味着相同的入口和您每次都可以稍作不同。 Th是一个特征,而不是问题。没有状态:这意味着没有记忆。每次您输入“记住”对话时,都必须提供所有相关的背景信息。这种观点很重要,因为它定义了工作方法。您不能更改模型本身,但是您可以完全控制入口。所有优化的关键是如何构建最有效的输入文本(即上下文)。指导模型生成预期的出口。 “ Speedword Project”曾经很受欢迎,但强调要找到完美的魔法咒语。这种方法在实际应用中不可靠。这是因为模型更新可以使“咒语”失败,而真实的输入比单个语句中的说明要复杂得多,比单个语句中的说明更为复杂。更精确,更精确的系统概念是“上下文工程之间的差异”。背诵咒语。上下文工程:A是为了构建自动化系统,例如信息管道的设计。该系统负责在完整上下文中包装,然后在模型中对数据库,文档等上的信息自动跟踪和合并信息。正如Andrej Karpathy所说,LLM是一种新型的操作系统。我们的任务不是给出零碎的命令,而是容纳执行它们所需的所有数据和环境。简而言之,“上下文工程”是关于创建“超级入口”工具箱。我们听到的各种时尚技术(耳朵,代理等)只是此工具箱中的工具。只有一个目标。它是以最合适的格式和最合适的时刻以最有效的信息来馈送最有效的信息。以下是工具箱的一些中心元素:指令:问题命令是最基本的。这意味着直接告诉模型该怎么做。例如,订购“玩专家”或显示一些示例nd让他们相应地学习。知识:您必须记住要指出“内存”在模型本身中没有内存。聊天机器人在他身上,一起发送聊天记录。如果记录太长,请创建“摘要”或仅保留最后的对话。工具:改进的生成搜索(RAG):为“开放书考试”提供参考书。为了防止毫无意义的含义模型(骆驼),首先找到其知识库的相关信息(例如公司文档),然后将“参考”和问题传递给模型,以便您可以客观地回答。特工:请单独“验证”。这是一个高级formhas的演出。我们不再预先准备所有信息,而是一个智能的“机构”确定您需要哪些信息,然后使用工具(例如搜索互联网或搜索数据库)查找答案并总结它们以最终解决问题。简而言之,所有这些技术,无论是简单的还是复杂的,都可以回答此任务n。 “如何为LE创建最完美的条目?”上下文工程的实用方法使用了执行科学实验而不是艺术创作的LLM。您不能相信猜测。您必须批准测试并进行验证。工程师的主要功能不是编写引人注目的建议,而是知道如何通过系统不断改进系统。首先,清楚地考虑LLM输出(内容,格式等)的终点。最终组装),开始建筑物。它完成了“精细的组装测试”。VEA当前常规的上下文工程的最新博客和视频详细介绍了四种中心方法,并显示了Langgraph和Langchain生态系统的Langgraph和Langsmith如何帮助开发人员有效地实施上下文工程。博客地址:共同代理的NTEXT工程视频地址:代理上下文工程(Langchain)